最新Windowsソフトウェア事情(第31回)
Windowsコンソーシアム顧問 高橋 三雄
(mtaka@fsinet.or.jp)
情報収集の強い味方
みなさんはこの変化の激しい情報技術の分野においてどのような情報収集の方法を実践されているであろうか。当然のことながらインターネットはもっとも重要な情報収集のツールになっているはずである。たしかに私も専門の経営意思決定支援関連ソフトの現状を調べるためにインターネットを探索しているが、その結果、Vol.38で紹介したようにインターネットなしにはとても入手できない豊富な情報(デモソフトを含めて)を一日にして得ることができたのである。
ところで、それではインターネットにアクセスできればどのような情報でも即座に入手できるかといえばそうでもない。もしそうなら日ごろ読んでいる新聞や雑誌も無駄な出費となるだろうし、また、本誌も会員のみなさんから無駄だからやめろ!という声が大きく聞こえてくるはずである。新聞や雑誌もまた情報収集において大きな役割を果たしていることは厳然たる事実である。情報収集の方法としてはさらに、各種のデータベースがCD-ROMのメディアで利用できるようになった。私も本連載の第一回で紹介したようにComputer Selectという名前のコンピュータ関係データベースをこの5,6年、米国から購読している。これは月刊のデータベースであり、そこにはコンピュータ関連雑誌120誌からの記事が7万件、パッケージソフト4万5千本、ハードウエア3万種類そして1万数千社のコンピュータ関連企業の情報が高度な検索機能とともに収録されている。このデータベースにもとづいて73のカテゴリーに分類された豊富なソフトウエアの世界を探訪するのが私の日課となっている。
CD-ROM版データベースとしてさらに、日本統計年鑑(統計情報研究開発センター)、日経会社情報(日本経済新聞社)、日本国勢図会(国勢社)も参照している。また、英文のコンピュータ雑誌ByteとWindows SourceもそのCD-ROM版(年4回)を購読している。このようなCD-ROM版データベースは高度な検索機能が利用できることがその最大のメリットであるが、さらに当然のことながら情報は最初から電子化されているので、検索された結果をすぐさま、ワープロソフトやデータベースソフトに移して自分の個別の目的にそった情報の整理や利用ができることも見逃せないメリットである。
さて、紙に印刷された新聞や雑誌から得た情報となると従来はスクラップブックに貼り付けて整理しておき、何か情報を探したいときには膨大なスクラップのページをめくって検索するという作業が求められた。もちろん、最近では新聞記事もデータベース化されオンラインで検索したり、CD-ROM版も利用できる。さらには読売新聞などからは新聞の縮刷版がCD-ROM化されて発売されるようになったので新聞記事の利用の仕方も変わってくるだろう。しかし、依然として昨日、今日の新聞記事の中で気になった記事を何らかの方法で保存しておこうとする気持ちは変わらないのである。
最近は手軽な電子ファイリングシステムが低価格で利用できるようになった。私もその代表機種であるVisioneer社のPaperPortを利用している。また、ソフトとして「超整er(ノヴァ)」もためしてみた。それぞれイメージとして情報を保存し、イメージに与えたキーワードにもとづいて検索できる。しかし、イメージなのでそこに含まれる文字情報をワープロソフトなどで利用することはできない。そうしたときにイメージとしての文字を文字として認識させるソフトの支援が役立つことになる。PaperPortにも超整erにもこの文字認識機能(OCR、Optical Character Recognition)機能がついていることはいうまでもない。
今回は単体のOCRソフトとして定評のあるe.Typist(メディアドライブ社)を具体例として新聞や雑誌記事を即座に文字情報(電子情報)にすることを検討してみよう。なお、e.Typistはその機能限定版がたとえば私が利用しているキャノン社のスキャナーにバンドルされており、私自身すでに利用した経験もあった。今回は単体としての製品版を使ってOCRの高度な機能を体験することにする。
OCRソフトはスキャナーで読み込んだイメージの中から文字を認識してテキストに変換することがその基本機能である。しかし、現実の情報(イメージ)は写真や図がまじったり、表が含まれていたり、また、段組が多用されたり、文字のサイズやフォントもさまざま、さらにはイメージの質もさまざまである。テスト用の紙面にもとづいて文字認識の精度を比較するといったこともよく行われるが、本欄では当然のことながら、たとえばWindows Viewを対象として文字認識の実際をためすことはいうまでもない。
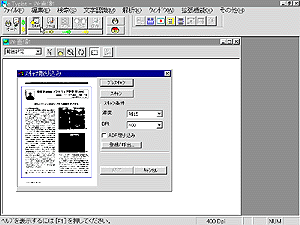
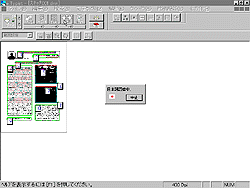
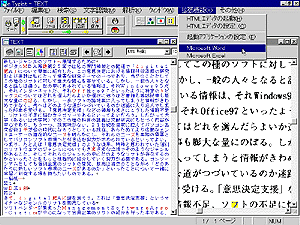
図 1はスキャナーから紙面を読み込もうとしているところである。中央にスキャナー取り込みのウィンドウが開かれるのでプレスキャンボタンをクリックし、Windows Viewのページをプレスキャンした。なお、ADF(オートドキュメントフィーダー)にも対応しているので複数のページを連続して取り込んで、それらのページを自動的に文字認識させることも可能である。プレスキャンしたページは図の枠で囲まれているように文字認識させたい範囲をマウスで選択し、スキャンボタンをクリックして実際のスキャンを行えばよい。それによって紙面の枠といった文字認識に邪魔になるイメージをあらかじめ排除できる。
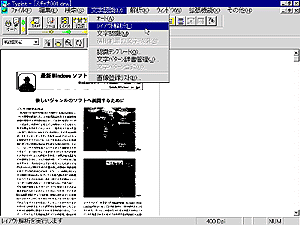
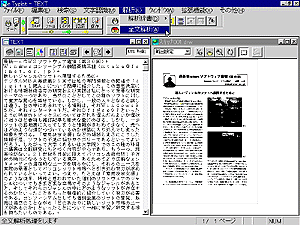
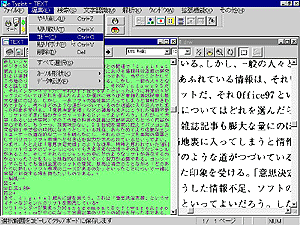
紙面を見てわかるように、そこには私の写真とか原稿の中で参照している図版が含まれている。また、段組された範囲の文字認識にあたっては各段組をどのような順序で認識していくのかその指定を行う必要がある。文字認識ソフトの優劣をつける一つのポイントはこうした多様な紙面の中から文字を含む領域を認識し、さらにそれをどのような順序で文字に認識していったらよいか、その解析機能のよしあしであろう。本欄はソフトの評価を目的としてはいないが、e.Typistの場合にはすぐれたレイアウト解析機能を含んでおり、図 2のように、文字認識メニューの「レイアウト解析」を選択することによってイメージの領域を文章、表そして図のいずれかに自動認識してくれる。なお、ソフトの操作にあたってはほとんどの機能が画面上段のメニューバーのボタンに割り当てられており、ボタンをクリックするだけで操作できる。
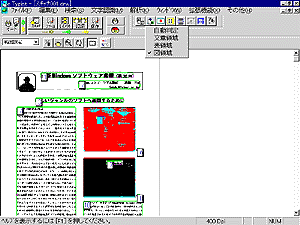
レイアウト解析した結果は図 3のようにイメージ上に表示された。各領域には番号がふられ、この番号順に文字認識が実行され、それらがつながれて最終的なテキストファイルが作成される。各領域の種類(文書、表、図)はソフトが自動的に認識してくれるが、場合によって自分で指定したり、あるいは認識された内容を確認できる。そのためには図のように、イメージ上で範囲をマウスで選択し(実際の画面上では範囲をマウスでクリックしたときに文書領域は青、図領域は赤で示される)、メニューバーの領域種別指定ボタンをクリックすることで図の上段のようなリストが表示される。ここで種別を変更することも可能である。また、領域は文字認識にあたってその順序を変更することも可能である。
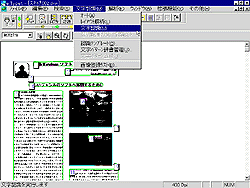
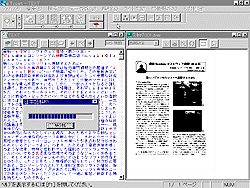
レイアウト解析(および領域種別設定)が終わると実際に文字認識を行うことができる。そのためには図 4のように文字認識メニューから「文字認識」を実行すればよい(あるいは認識ボタンをクリックする)。それによって図 5のように画面上に「日本語認識中」の表示が示され、1ページ分であれば10数秒というごく短時間で認識が完了する。なお、英文だけの紙面から文字認識する場合は認識言語ボタンをクリックして英語を選択することで文字認識の精度や速度があがる。
文字認識された結果は図 6の左側のように表示された。英字の認識がもう一つという印象であるが、本文中の日本語に関してはほとんど認識のエラーは見られない。もちろん、100%確実というのではないので、次に編集作業に進むことになる。その場合、e.Typistには文章解析機能が用意されており、それによって和文として不適切な個所を認識し、そのエラーの可能性を指摘してくれる。また、図でもわかるように、画面右側には認識されたテキストと連動した形で紙面イメージが表示される。つまり、テキスト上でこれはと思われる文字を選択するとそれが紙面(イメージ)上のどの部分であるかが連動して選択、表示されるのである。イメージは画面上段の拡大ボタンで任意の倍率で拡大表示できるので、誤りと思われる文字に対応する紙面上の部分と対比し文字の確認や修正が可能となる。
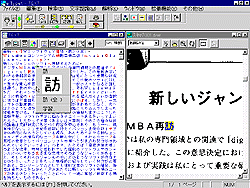
解析メニューから「全文解析」を選択、実行すると画面上には図 7のように「日本語解析中」の表示があらわれ、やがて問題個所が画面上では黄色で表示される。たとえば図 8は黄色で表示された「再訪」の訪の字を選択したところである。それによって画面右側のイメージの上で「訪」に対応する個所が表示され、文字認識の結果を確認ができる。この段階で誤りが分かれば直接、入力しなおしてもよいし、あるいは図のように選択した文字の上でマウスの右ボタンをクリックすると候補の文字リストが表示されるので、その中から選択してもよい。図では最上段が実際に採用された文字、その下が文字のイメージ、そしてそれ以下に候補の文字がリストされる。いまの例では誤認識された文字が見当たらなかったために、文字認識の正しさを確認しただけに終わってしまったが、この機能は大変に便利であると思われた。
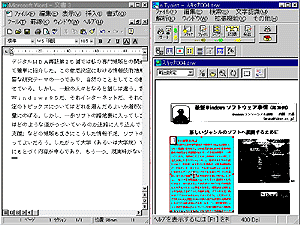
OCRソフトで認識された結果はたとえばワープロソフトなどに移してさらに編集したり、ファイルとして保存されたりするだろう。多くの場合、ワープロソフトや表計算ソフトがOCRソフトで認識された結果を待っている。そこでe.Typistには必要なソフトをe.Typistのメニューから直接、起動できるように上段の拡張メニューに登録できるようになっている。図 9はWordとExcelを登録した様子を示している。また、図からわかるようにHTMLへの移行機能もそなえられている。
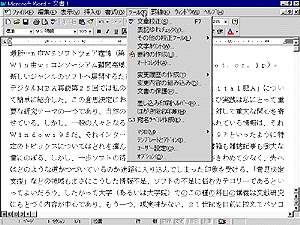
文字認識されたテキストがそのままWordなどのワープロソフトへ移ってくれればありがたいのであるが、これはとりあえずコピー/ペースト操作で行うようである。図10はいまの例についてテキストをすべて選択してコピーし、それを画面右側のWordの編集画面上に貼り付けた様子を示している。これからあとはWordの高度な編集機能を利用して編集すればよい。念のため図11にe.Typist で認識したテキストをWord上で編集しようとしている様子を示しておいた。Wordのツールメニューには文書校正をはじめ高度な編集機能が満載されている。
ところでe.TypistはまたOLE2対応となっている。それによってたとえば図12のように、画面右側のイメージから任意の範囲を選択し、それを直接、ワープロソフトの編集画面上にドラッグ/ドロップすることによって、その範囲の文字認識を実行し、その結果をワープロ画面上に入力してくれる。これはまた、テキスト領域だけでなく、図版を含む領域もそれをRTF(リッチテキストフィールド)として指定すれば、文字だけでなく、図もワープロソフトの編集画面上に置くことができる。
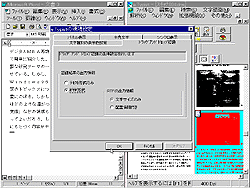
図13は「その他」メニューから「環境設定」を実行して、ドラッグアンドドロップの条件設定を行っているところである。ここでRTF形式を指定すればよい。それによって図14のように、画面左側のイメージから図まじりの領域を選択し、左側のWord上にドラッグ/ドロップすると領域に含まれる文字が認識されるとともに、同じ領域に含まれる図もワープロソフトの編集画面上に移された。このほかにも表の認識とか縦組みのテキストの認識とか、OCRソフトとして高度な機能が含まれており、このジャンルのソフトとして高い評価を得ていることがうなずけるソフトであるといってよい。私自身もこれからは新聞、雑誌も大いに活用して情報収集の範囲を広げたいと思っている。
(筑波大学大学院 経営システム科学 教授
http://www.fsinet.or.jp/~kaikoma/)
|
|
Windowsコンソーシアム技術者交流会席上にて、
左から二人目が筆者 |
Contents
Windows Consortium ホームページ